
If you are a developer, and want to learn more about microservices – you should definitely participate in our code-along this fall. We will publish three challenges related to microservices in November and then gather together at a microservice meetup the 4/12 to discuss different ways to solve the challenges and learn from each other.
The challenges will be published on the 6/11, 13/11 and 20/11 in Citerus blog and on our LinkedIn page. You can find the first challenge in our blog.
Dealing with databases in a microservice structure can sometimes be a challenge, so this week we will be handling reads from databases.
Centralized Database
With microservices we have moved away from centralized databases and instead letting each service own its own data. This is giving us benefits in such as loose coupling and we can tailor the data for the service. However, data has become a large topic in microservices.
Typically with a centralized database we are looking to normalize the data in order to simplify writes and having things at only one place. Taking this mindset into microservices, where each service owns its own data, some situations can yield issues due to a lot of internal service communication, complex error handling and slow response times.
That is why we need to assess each situation and sometimes adopt a new point of view where it is okay and even encouraged to denormalize data and favor duplication instead of keeping it at only one place. This is something we are going to take a closer look at in this week’s challenge.
If you’re looking for Challenge 1, you can find it here. And, don’t forget to grab a spot to our Microservices MeetUp with Chris Richardson at the 6th of May.
Challenge 2
For our previous challenge we helped a company which specialize in squeaky toys for dogs. They encountered an issue with writing to the database as they needed to ensure consistency across service boundaries. Since then, the webshop has been flourishing and with an increasing number of users they are starting to see more problems. This time, it is with reading from the database.
The problem was addressed during a backlog refinement meeting when the product owner added a new story to their backlog.
“I have had a few talks with customer support the last couple of weeks and we have an increasing number of customer support cases and our feedback channels are full of users who are complaining about the Customer pages which contain the overview of the customers activity with us. For example the order history. It is apparently super slow and sometimes the page is just white. This needs to be solved.”
One of the team members connects their laptop to the tv in the room and presents the team dashboard.
“This mimics the health of our system. We have seen that the response times have slowly increased along with a few timeouts when fetching the order history. “
Another team members joins the discussion.
“Ah, but isn’t this as expected? When we developed the API gateway we took a shortcut because we did not yet have that much traffic. The problem is that when the frontend ask for “Give me all orders” we are doing a few things:
Firstly, we fetch all orders for that user from the order service.
Secondly, for each product on each order we fetch the product details from the product service.
This means that for one call from the frontend we might end up with quite a few internal service calls. This worked when each customer had one or two orders but for frequent users with a large order history, we are having some troubles.”
Current situation
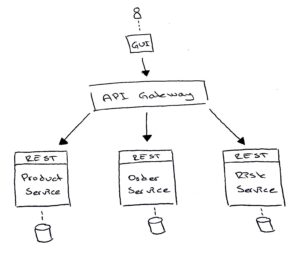
The team has built an API-gateway which serves the front end with data. The API-gateway takes a request from the front end, convert it into internal calls, aggregate all the data and serves a nice json-blob to the frontend with what was requested.
Right now for one of the use cases, the order history, this approach has turned out to be underperforming and there is a need to rethink when this aggregation is done.

GET /customer/{id}
The blob which is returned to the gui with the source of the data
The project has taken an approach where the data is owned by the service who creates it. If anyone wants to read that data, that service needs to query for it. That is one of the reasons why they have a problem today and it is time for a change. Could you help the team to show that duplicated data is not the devil and can be the solution to the problem above?
By aggregating all the data needed to visualize the order, the API-gateway could make only one request to get everything needed. But how do we aggregate the data and where does the aggregation take place?
Please link your solution below or comment on your approach!
And again, if you’re looking for last weeks challenge, you can find it here.